The greatest benefit of using Salesforce is it’s configurability. You can create (almost) endless objects and (almost) endless fields to define business processes. With the combination of Visualforce, Apex, LDS and the Platform itself, we can create objects and fields to drive UI elements, making them completely customizable. This makes development on the platform super easy and maintaining things that can change over time becomes easier.
However, when we make code or visualizations data driven, we create a problem:
You can only deploy configuration and code, not data in Salesforce!

That’s why you have seen a lot of companies pop-up that have created apps to help you deploy data between environments. This is a great idea, but can be relatively costly.
I spent some time thinking about this problem and got some significant help from folks on the Salesforce team here about how to do this. Luckily we have done some things in other areas that are KIND of similar, just needed some heavy lifting for this use case. I’m sure I’m not alone in this, where we have many different sandboxes, but the need to send data from environment to environment like a traditional deployment. One example is Products, where we start selling a brand new Product and there are other processes that are dependent upon the Product data. Wouldn’t it be nice if we could create the Product in our development environment, write the automation that is necessary and deploy the code/configuration and also the Product info? Instead, we end up data loading “stuff” to these environments. In this Product example, we data load the Products and then the Price Book Entries, which is kind of a pain because you need to know the Price Books you are needing to insert entries for before you can insert the entries. What a manual process…
Wouldn’t it be nice if you could just write an app or tool to help you deploy some of these data elements to different environments?
Wouldn’t it be weird if the purpose of this blog was just to say yes it would be a neat idea, but too bad you can’t do it? Bummer, you’re in for an explanation on how you COULD do this.
Luckily, I HAVE done this and it didn’t take a ton of time, just some hurdles to get over, but the rest just came together. The general design is:
- Created Named Credentials between all environments you want to be able to send or receive data from
- Create a REST service to accept a POST to the service that includes some amount of info
- Create a method within the REST service that will format data in the way that the REST service needs
- Create a generic Utility that will take an object, and return the list of fields for that object
- Create a generic Utility that will return a mapping of field to value for fields that have been filled for a record
- Create a generic Utility that will take a list of Object Ids and related records, return all of the objects and turn them into JSON for easily sending through a service
We can be done at this point, but we can extend it further by creating a UI to send data to other environments and batching or queueing requests to not overload the service payloads.
First, let’s talk about Named Credentials. I feel like I could spend a whole blog on this, but instead, please refer to other blogs on how to set this up. The gist is to first, create a Connected App in the environment you want to send data to (target). Then in the source org, create an Auth Provider, making sure to put the callback URL back to the Connected App in the target org. When that is complete, create your Named Credential in the Source org using OAuth2 or either using Username and Password.
From there, when you make your callout, you just need to do something like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| HttpRequest req = new HttpRequest(); | |
| String callout = 'callout: ' + NAMED_CREDENTIAL_NAME + '/services/apexrest/REST_EndPoint'; | |
| req.setEndpoint(callout); |
We are essentially just putting the Named Credential name in the path of the callout to use it’s credentials in the callout itself. Once we have the Named Credentials set up, we can start our generic stuff:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static Map<String,Object> getListOfFields(String sobjectType){ | |
| SObjectType objectType = Schema.getGlobalDescribe().get(sobjectType); | |
| Map<String,Schema.SObjectField> mapObjectFields = objectType.getDescribe().fields.getMap(); | |
| Map<String,Object> fieldMap = new Map<String,Object>(); | |
| List<String> fieldNames = new List<String>(); | |
| for (String field : mapObjectFields.keySet()) { | |
| Schema.DescribeFieldResult dr = mapObjectFields.get(field).getDescribe(); | |
| //Only add Custom, non-formula fields, non-auto number | |
| if (dr.isCustom() && !dr.isCalculated() && !dr.isAutoNumber()) { | |
| fieldNames.add(field); | |
| fieldMap.put(field,null); | |
| } else if (dr.isCreateable()) { | |
| fieldNames.add(field); | |
| fieldMap.put(field,null); | |
| } | |
| } | |
| return fieldMap; | |
| } |
This method will return a list of writable fields for a given object. This is item 4 in our list of items at the top. If we take our Product example here, we would do something like:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Map<String,Object> fieldList = new Map<String,Object>(); | |
| fieldList = getListOfFields('Product2'); |
This would return us a Map of the name of a field, and null values for each field as our returned generic Object.
Then, we can use another generic method to return all of the populated fields for a given object:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static Map<String,Object> sendWrittenFields(sObject record){ | |
| Map<String, Object> fieldsToValue = record.getPopulatedFieldsAsMap(); | |
| Map<String,Object> fieldMap = new Map<String,Object>(); | |
| fieldMap.putAll(fieldsToValue); | |
| List<String> fieldsToRemove = new List<String>(); | |
| fieldsToRemove.add('Id'); | |
| fieldsToRemove.add('OwnerId'); | |
| fieldsToRemove.add('id'); | |
| fieldsToRemove.add('ownerid'); | |
| //Always remove Id | |
| for (String s : fieldsToRemove) { | |
| fieldMap.remove(s); | |
| } | |
| return fieldMap; | |
| } |
This is item 5 in our list from the top. We will pass an sObject to the method and will get back a Map of Field Name to value. We remove system fields like OwnerId and Id that I don’t really want to be deployed. You may want to enhance this list. From these two methods we then know the total list of fields on an object and the fields that have a value for each object.
From here, we can then create a generic method to JSON objects and their potential children and get the correct structure.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static String jsonSetup(List<String> objectIds, Map<String,String> queryHelper){ | |
| Map<String,Object> masterMap = new Map<String,Object>(); | |
| List<String> objIds = objectIds; | |
| for(String s : queryHelper.keySet()){ | |
| List<String> fieldList = new List<String>(); | |
| fieldList.addAll(getListOfFields(s).keySet()); | |
| String query = ' SELECT ' + String.join( fieldList, ',' ) +' FROM ' + s + ' WHERE ' + queryHelper.get(s) + ' in :objIds '; | |
| List<SObject> records = Database.query(query); | |
| Map<String,Object> relatedRecords = new Map<String,Object>(); | |
| for(sObject r : records){ | |
| relatedRecords.put(r.Id,sendWrittenFields(r)); | |
| } | |
| masterMap.put(s,relatedRecords); | |
| } | |
| String serializedJSON = JSON.serialize(masterMap); | |
| system.debug('REST_Utilities.jsonSetup: ' + serializedJSON); | |
| return serializedJSON; | |
| } |
Here is item 6 from our list from the top. This method will take a list of sObject Ids as a String, and a Map of an sObject API name and it’s relation to the list of Ids. For example, if we wanted Accounts and all of their Contacts, we would pass a list of Accounts as objectIds, and a Map that has the values of Account with it’s corresponding value of Id and Contact with it’s corresponding value AccountId. This is useful so we can build a dynamic relationship of objects. Creating this manually would look like this:
Map<String,String> objMap = new Map<String,String>(‘Account’ => ‘Id’, ‘Contact’ => ‘AccountId’);
In the Product case, we want the Map to look something like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Map<String,String> objMap = new Map<String,String>(); | |
| objMap.put('Product2','Id'); | |
| objMap.put('PriceBookEntry','Product2Id'); |
If we were to pass this in to the generic JSON, it would return us a list of all of the Products we have the Ids for, as well as their related Price Book Entries. The problem here is we don’t really know which price books these belong to, because the price books may have different Ids in all environments depending on sandbox refresh schedule and how they were created.
If we use just this information above, using the Generic JSON setup method, we will get back objects of Product2 and PriceBookEntry, and how they are related. This is a great first step. Up to this point, we could use this for any sObject and related sObjects with an almost unlimited number of objects to be passed in. The limitation here would be the size of Lists or String size our JSON can support.
If we then get specific, we can create a Method specific to this use case to pass information to our generic methods to return exactly what we need. Here is an example:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| public static String setupJson(List<String> productIds){ | |
| //get list of Apttus products and add to list of Products to return to insert/update | |
| //this will be mapped to the Parent product later | |
| List<String> updateIds = new List<String>(); | |
| updateIds.addAll(productIds); | |
| //setup object structure dynamically with objects and relationship to master object | |
| Map<String,String> objMap = new Map<String,String>(); | |
| objMap.put('Product2','Id'); | |
| objMap.put('PriceBookEntry','Product2Id'); | |
| String jsonSetup = REST_Utilities.jsonSetup(updateIds, objMap); | |
| //get Product objects back to update them with a Pricebook attribute | |
| //will be used in target org to map source org PriceBook Id to name | |
| Map<String,Object> productFieldList = new Map<String,Object>(); | |
| productFieldList = (Map<String, Object>) JSON.deserializeUntyped(jsonSetup); | |
| List<Pricebook2> pricebooks = new List<Pricebook2>([Select Id, Name from Pricebook2]); | |
| Map<String,String> pMap = new Map<String,String>(); | |
| for(Pricebook2 p : pricebooks){ | |
| pMap.put(p.Id, p.Name); | |
| } | |
| productFieldList.put('Pricebook2',pMap); | |
| String serializedProduct = JSON.serialize(productFieldList); | |
| system.debug('json: ' + serializedProduct); | |
| return serializedProduct; | |
| } |
In this method, we are passing our list of Ids (or productIds, as I call them) and then pass info to our generic JSON method, including the Ids we want to use and the related Objects we want back. We also need all of the related Price Books so we can match them in the other environments. Finally, we will add a new attribute to our returned Map of Product2 and PriceBookEntry objects called Pricebook2 and the related Price Books we found from this environment. Serialize these bad boys up and then send along the wire.
From there, it’s a process of creating a service that can accept this kind of format and does the right thing with them. Some issues that will need to be resolved are the object Ids if you want to upsert/update existing data. Just make sure you create Maps of source org Id to some kind of identifier, like SKU, and then in the target Org Map SKU (or other identifier) to the new Ids of the Org.
One pretty interesting feature that I don’t think we use much is to use Map notation for an object. If we get a Map returned of a single Object which includes the Field Name and the corresponding value, we can use something like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| //create a template for each Product2 | |
| Map<String,Object> prodTemplate = getListOfFields('Product2'); | |
| //deserialize Product2 from JSON | |
| Map<String,Product2> prodMap = (Map<String, Product2>) JSON.deserialize(prodSerialize, Map<String,Product2>.class); | |
| //for each Product2 returned loop through | |
| for(String p : prodMap.keySet()){ | |
| //create new Product2 object | |
| Product2 prodToInsert = new Product2(); | |
| //initialize new Map for fields and values | |
| Map<String,Object> prodValues = new Map<String,Object>(); | |
| //use template for Product2 to populate for current object | |
| prodValues.putAll(prodTemplate); | |
| //populate Map with written values from this specific Product2 | |
| prodValues = sendWrittenFields(prodMap.get(p)); | |
| //from our Map, populate Product2 directly with put of field and value pair | |
| for(String field : prodValues.keySet()){ | |
| prodToInsert.put(field,prodValues.get(field)); | |
| } | |
| } |
Notice the line putting values into a prodToInsert (Product2) from a Map, just like working with a Map. Did you know you could do that??
From here, we can add prodToInsert to a List and insert it or upsert it as we should have all attributes from the source org, except fields that we can’t use (like old Id or something).
Once you have your automation in place to accept the incoming JSON, that’s kind of it. You can use Execute Anonymous to send the data, or you can build a UI to send or schedule batches or queueables. To test, you can just do something like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| List prods = new List(); | |
| prods.add('productId1'); | |
| prods.add('productId2'); | |
| prods.add('productId3'); | |
| prods.add('productIdN'); | |
| //make sure to change the name of the class to wherever you send data to the generic JSON from | |
| String jsonString = Product_RESTClass.setupJson(prods); | |
| HttpRequest req = new HttpRequest(); | |
| String callout = 'callout:' + Named_Credential + /services/apexrest/PRODUCT_REST_ENDPOINT'; | |
| req.setEndpoint(callout); | |
| req.setBody('json=' + jsonString); | |
| req.setMethod('POST'); | |
| Http http = new Http(); | |
| HTTPResponse res = http.send(req); | |
| System.debug(res.getBody()); |
This will actually do the object setup, correctly format it and send it to whatever environment you use for your Named Credential and EndPoint combo.

You may have concerns about JSON size or things being send across getting lost. If you plan on sending large amounts of data, consider chunking the data into smaller sections, and sending them using Batch or Queueable. I have implemented this process with Queueable and seems to work well.
I also created a quick UI for our team to be able to send things along, which pulls in our environment connections and creates Queueable jobs which finish the execution.
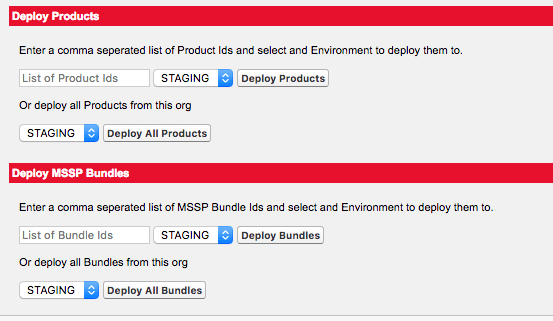
In conclusion, this process is extremely flexible. The difficult parts here are:
- Being able to correctly link parent and child objects in the target org
- Being able to remove fields that create too much complexity in the target org
- Getting familiar with how Named Credentials work with callouts
Let me know if you have questions. I purposefully left out the customized code that processes the inbound JSON as I think this would need to be customized for each use case you have and possibly your own org. But the idea is simple. Accept incoming objects, format them to match your source org, match Ids as necessary based on a common key and insert/update/upsert parent records while correctly parenting children and either inserting, updating or upserting. LASTLY, I realize the UI is in the standard UI. This could easily be done in LEX, but my admin tools pages are not yet migrated.
